Designing a Bot to Beat the S&P
My second project — designing a mini trading desk.

I was fortunate enough to start my career in banking, working in research, identifying trade opportunities for the bank's customers and trading floor. I learned a lot during that time — obviously, seeing how Wall Street operated up close. Everyone on the floor had access to the most cutting-edge data, and there were experts in every asset class whose entire job was to identify trading opportunities.
When you see that and start thinking about your own personal investments, the conclusion I came to was pretty straightforward: there's no way I could replicate those resources or apply that kind of time for it to make sense for me to do any form of day trading. So, as is advised and as most people do, I put my hard-earned cash in ETFs and rode whatever stock market wave came along.
When I started building with Claude Code, I wondered if I should re-evaluate those assumptions — now that I could build a bot with unlimited time.
This isn't an article about investment advice. Just a bit of background as to why I thought I could build a bot that might do a better job than an ETF.
The seed of an idea
So if I can build a bot that is on all the time — that doesn't sleep, doesn't get distracted — and couple that with freely available data rather than expensive investment-grade feeds, is that enough to beat an ETF?
The specific opportunity I landed on was earnings. Taking a page from Warren Buffett's playbook, identifying opportunities based purely on fundamentals felt like the safest and most straightforward approach for a bot in this space. As we all know, every quarter thousands of companies report their results. Analysts publish estimates beforehand, and the market reacts when those estimates turn out to be wrong. A bot that's constantly monitoring revisions, fundamentals, and sentiment across hundreds of companies might have a chance to beat the index.
With that seed, I did a bit of research into what it would take to build an earnings bot.
Modelling it after a bank
When I sat down to design the system, I thought about how a trading desk actually functions. There are three distinct functions: research, risk, and trading. And the conclusion I reached is that only the research function required an LLM. Risk and trading could be entirely deterministic — hard-coded rules that no amount of LLM confidence could override.
Research is where the LLM earns its keep. But even here, it doesn't see everything — deterministic pre-screen checks first identify promising candidates based on factors like earnings revision momentum, historical surprise patterns, and fundamental quality. This keeps LLM costs from ballooning. Only candidates that pass the pre-screen get sent to the LLM, which analyses the data and determines whether there's an opportunity the street is undervaluing.
Risk takes the LLM's recommendation and passes it through purely deterministic gates. Position sizing, exposure limits, sector concentration, circuit breakers — all hard-coded rules that the LLM cannot override. No single trade exceeds a fixed percentage of the portfolio. If the portfolio draws down beyond certain thresholds, trading pauses automatically. The LLM can be as bullish as it likes — risk management has the final say.
Trading executes whatever survives the risk gates. Bracket orders with stop losses and take profit targets, all automated.
On a real trading floor, the person identifying the opportunity is not the same person controlling the risk. Those functions are deliberately separated so that enthusiasm can't override prudence. I wanted the same principle in the bot. It trades real money without me approving each trade. The only reason I'm comfortable with that is because the risk controls are completely outside the LLM's reach.
Here's the pipeline:
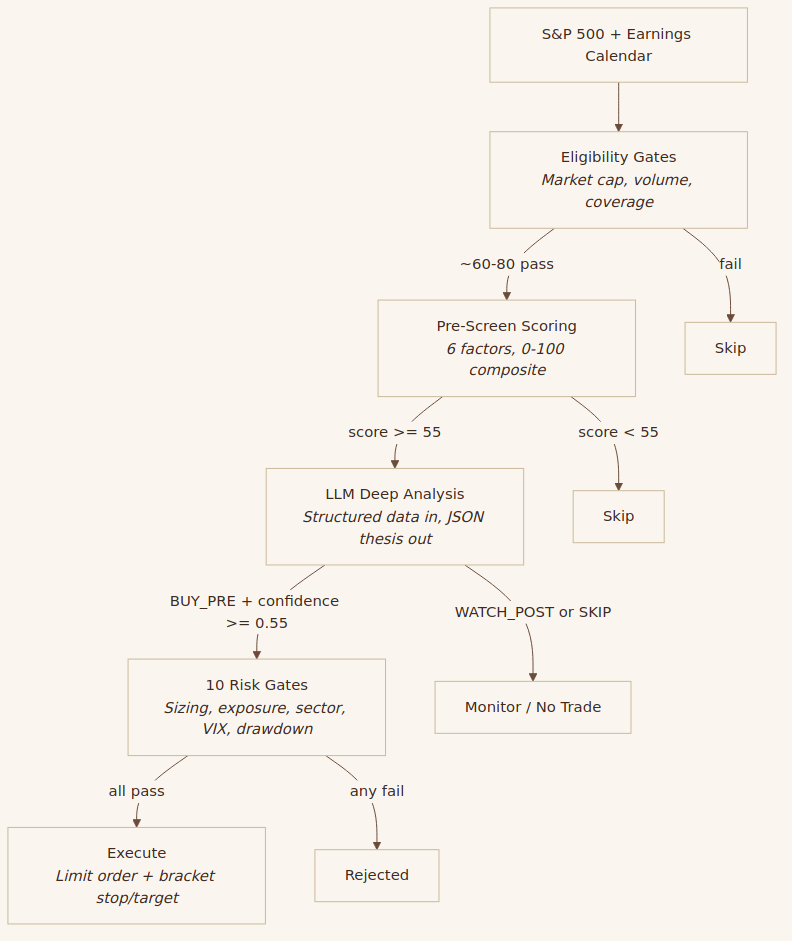
Each stage is a filter. Out of roughly 150 earnings events per quarter, maybe 60–80 pass eligibility, 25–35 pass pre-screen, 8–12 get a BUY_PRE from the LLM, and 6–10 survive the risk gate to become actual trades.
What the LLM might be good at here
My thinking, based on the research in the appendix below, is that LLMs won't be doing anything remarkable here. They won't be superintelligent. They won't be predicting stock prices or timing the market.
My hypothesis is that it might have an edge in two ways. One, it can systematically apply the same analytical framework to any company to determine whether it's undervalued by the street. It doesn't get tired, it doesn't cut corners on the fifteenth analysis of the day, and it doesn't let its opinion on the last stock bleed into the next one.
And two, it gets fed the most up-to-date freely available information — earnings estimates, analyst revisions, financial statements, news — at the exact moment it needs to make a decision. An analyst covering 15–20 stocks might miss the latest revision from one broker while they're busy with another. The bot sees everything, every time.
So the edge — if there is one — isn't intelligence. It's consistency and recency. The academic research is encouraging — a study out of Chicago Booth showed that LLMs can match or outperform financial analysts in predicting the direction of earnings surprises, even from standardised financial statements alone. The bot doesn't need to be right on any single trade. It needs to be right more often than it's wrong, across a large enough sample, with tight enough risk controls that the losses are contained. That's the whole game.
Two ways to trade earnings
I designed the bot to trade earnings in two ways, both to make the most of the research pipeline. The thinking behind each:
Pre-earnings positioning is the higher-conviction play. The idea is that if the bot's analysis suggests consensus is too low, you buy a few days before the announcement. If it's right and the company beats, the stock gaps up. If it's wrong, the stop loss limits the damage.
Post-earnings drift is the lower-risk approach. Here, the bot waits for the announcement, confirms the surprise was significant, and enters to ride the drift — the documented tendency for stocks to keep moving in the direction of the surprise for weeks afterwards. You miss the initial gap, but you're trading on confirmed information rather than a prediction.
Having both means the bot can capture value at two different points in the earnings cycle — before the announcement on conviction, and after it on confirmation.
What's next
The bot is built and trading. In the next post, I'll share how it performed in historical simulation across three years of earnings data, and what the first few weeks of live trading have looked like.
See you in the next one ✌️
Appendix: Academic research that informed the design
A few of the papers and findings that shaped how the bot was put together:
LLMs as analysts, not price predictors. FINSABER (2025) found that LLM-generated trading strategies fail to outperform buy-and-hold over longer timeframes. The takeaway: use LLMs as signal enhancers and qualitative reasoners, not as autonomous decision-makers. This is why the LLM only touches the research function.
LLMs can match or outperform analysts on earnings direction. The Chicago Booth study (Kim, Muhn & Nikolaev) showed that GPT-4 achieves ~60% directional accuracy on earnings predictions using chain-of-thought reasoning — outperforming the median financial analyst. This underpins the core hypothesis.
Deterministic risk management, separate from the LLM. Multiple studies informed this. FINSABER showed LLMs are overconfident and overly aggressive in bear markets. Kang & Liu (2023) documented hallucination of financial data. The conclusion: the entire risk stack must be deterministic code with no LLM override capability.
Structured data in, structured output out. Research consistently shows LLMs hallucinate financial data and struggle with numerical computation (Kang & Liu, 2023), while excelling at interpreting pre-computed numbers (Kim et al., 2024). So the bot never asks the LLM to calculate — it feeds structured data in and gets a structured thesis out.
Adversarial bull/bear framing. The TradingAgents framework (UCLA/MIT) showed that adversarial researcher debate reduces hallucination and overconfidence. The bot's prompt forces the LLM to construct both a bull case and a bear case for every analysis, which serves a similar function.
Post-earnings announcement drift. Originally documented by Ball & Brown (1968) and extensively studied since — the tendency for stocks to continue drifting in the direction of the earnings surprise for weeks after the announcement. This is one of the most robust anomalies in empirical finance and the basis for the bot's drift capture strategy.